이번주부터 한 주에 하나의 논문을 읽어보려고 한다. 나 잘할 수 있겠지 ? ^_^
💬 논문 내용과 이 글에 대한 의견 공유, 오탈자 지적 환영합니다. 편하게 댓글 남겨주세요 !
원문 : https://arxiv.org/pdf/1706.03762.pdf
Abstract
dominant한 sequence transduction 모델들은 복잡한 RNN/CNN 구조
→ Attention 매커니즘만을 기반으로 하는 새롭고 간단한 구조의 Transformer 제안
2022. 3. 4 추가
Transformer 요약 : 학습과 병렬화가 쉽고 attention 구조를 사용하여 속도를 높인 모델
Introduction
Attention 매커니즘은 입력, 출력 간 거리에 상관없이 modeling을 할 수 있게 한다는 점에서 sequence modeling과 transduction 모델의 핵심적인 부분이지만 여전히 recurrent network와 함께 사용되는 경우가 종종 있었기 때문에 논문 저자들은 recurrent network 없이 attention 매커니즘에만 의존하는 모델 구조를 제안한다.
Background
Self-attention이란 시퀀스의 representation을 계산하기 위해 하나의 시퀀스에서 서로 다른 위치에 있는 정보를 가지고 attention을 수행하는 과정이다. (서로 다른 문장에 attention을 적용하는 게 아니다 이런 의미로 해석함)
Model Architecture
경쟁력 있는 neural sequence transduction 모델들은 대부분 인코더-디코더 구조를 가지고 있다.
- 인코더 : 입력으로 들어오는 symbol representations sequence (x1, …, xn)을 연속적인 representations sequence (z1, …, zn)에 매핑하는 역할 (1~n은 아래첨자)
- 디코더 : z가 주어지면 symbol의 output sequence (y1, …, yn)을 출력
** 디코더 부분 내용에 the decoder then generates an output sequence (y1, ..., ym) of symbols one element at a time. 이라는 문장이 있는데 one element at a time의 의미를 아직 못 이해했다 ㅠ
Transformer는 인코더-디코더 구조를 전반적으로 따르는데 인코더와 디코더에서 모두 stacked self-attention, point-wise fully connected layers를 사용한다.

1. Transformer encoder & Transformer decoder
1) Transformer encoder
- 두 개의 sub-layers(multi-head self-attention, wise-fully connected feed forward)로 구성된 레이어(그림 회색 부분) 6개로 이루어져 있다.
- 두 개의 sub-layer에 residual connection과 layer normalization을 적용했다.
- 각 sub-layer의 출력은 LayerNorm(x+Sublayer(x))이고 Sublayer(x)는 sub-layer 자체에 의해 구현된 함수이다.
- residual connection을 용이하게 하기 위해 embedding layers를 포함한 모델의 모든 sub-layer의 출력 차원을 512로 설정했다.
2) Transformer decoder
- 세 개의 sub-layersub-layers(masked multi-head attention, multi-head self-attention, wise-fully connected feed forward)로 구성된 레이어 6개로 이루어져 있다.
- 이후의 위치에 접근하지 못하게 self-attention layer를 수정했다. → position i를 예측할 때 i보다 작은 위치에 있는 것에만 의존하도록
** i가 철자 하나하나의 인덱스를 의미하는 게 맞나? 🙄
2. Attention

1) Scaled Dot-Product Attention
- dx 차원의 key, dv 차원의 value, 쿼리가 입력으로 들어온다.
- 키를 이용해 쿼리의 dot products를 계산하고 각각을 sqrt(dk)로 나눈 다음, softmax 함수를 적용하여 values에 대한 가중치를 구한다.
- output matrix는 아래와 같이 계산한다.
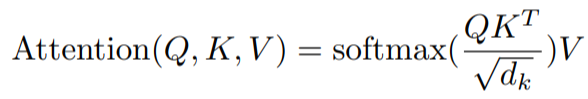
2022. 3. 8 추가
$sqrt(d_{k})$의 역할 : $d_{k}$의 값이 작을 때는 additive attention과 dot-product attention의 성능이 비슷하지만 $d_{k}$가 큰 값일 때는 dot-product attention의 성능이 훨씬 떨어지기 때문에 값 크기 조정 목적

2) Multi-Head Attention
- d_model 차원의 keys, values, queries를 사용하는 대신 dk 차원, dv 차원에 대해 학습된 서로 다른 linear projections을 사용하여 queries, keys, values를 linear하게 h회 투영하는 것이 유익하다는 것을 발견했다.
- queries, keys, values의 투영 버전에서 self-attention을 병렬로 수행하여 dv 차원의 출력 값을 산출하는데 최종적으로 산출되는 값은 아래와 같다.

3) Applications of Attention in our Model
- Transformer는 multi-head attention을 세 가지 방식으로 사용한다.
> 인코더-디코더 attention 레이어에서 queries는 이전 디코더 레이어에서 나오고 memory keys와 values는 인코더의 출력으로부터 나오는데 이 과정에서 디코더의 모든 위치가 입력 시퀀스의 모든 위치에 대해 배치된다. → sequence-to-sequence 모델에서 일반적인 인코더-디코더 attention 매커니즘을 모방
> 인코더에 self-attention 레이어가 포함되어 있기 때문에 인코더의 각 위치는 인코더 이전 레이어에 있는 모든 위치를 관리할 수 있다. ** ??
> ** 마지막 내용은 디코더 관련인데 문장 처음부터 이해불가여서 생략하였음 ..
3. Position-wise Feed-Forward Networks
attention sub-layer 뿐만 아니라 인코더와 디코더의 각 레이어들은 각 위치에 개별적으로 적용된 fully connected feed-forward network를 가지고 있다.

4. Embedding and Softmax
다른 시퀀스 모델과 유사하게 Transformer도 학습된 임베딩을 사용하여 입력 토큰과 출력 토큰을 d_model 차원을 갖는 벡터로 변환한다. 또한 디코더 출력을 예측되는 다음 토큰의 확률로 변환하기 위해 usual learned linear transformation과 softmax 함수를 사용한다.
5. Positional Encoding
Transformer는 recurrence, convolution이 없기 때문에 모델이 시퀀스 순서를 사용하려면 시퀀스에 토큰의 상대적인 위치(또는 절대적인 위치)에 대한 정보를 주입해야 한다. 이를 위해 인코더와 디코더의 하단에 위치한 입력 임베딩에 d_model 차원을 갖는 positional encodings을 추가한다.

Why Self-Attention
이 부분은 좀 더 꼼꼼히 본 후에 내용을 추가할 예정이다.
2022. 2. 28 추가
self-attention layer와 recurrent and convolution layer를 비교하고 왜 self-Attention을 사용했는지에 대한 내용이다. 논문 저자들은 아래 세 가지 이유는 고려하여 self-Attention을 사용했다.
① 레이어 당 총 연산 복잡도
② 필요한 최소한의 순차 연산 수로 측정할 때 병렬화할 수 있는 계산의 양 **핵심은 '병렬화'라고 생각한다.
③ 네트워크의 long-dependencies(장기 의존성) 사이 경로의 길이
🔍 ③ 관련 부연 설명(논문에 있는 내용)
- long-range dependencies는 sequence 변환 과제의 핵심 문제이다.
- 네트워크에서 forward&backward 신호가 이동해야 하는 경로의 길이는 의존성 학습 능력에 영향을 미치는 요인 중 하나다.
- 입력 및 출력 시퀀스에서 위치 조합 사이 경로가 짧을수록 long-range dependencies 학습이 쉽다.
**위치 조합이 정확히 뭘까

위의 비교 표를 보면 모든 면에서 self-Attention의 성능이 가장 좋은 것을 확인할 수 있다.
Training & Results & Conclusion
생략