이번 학기 하나 있던 텀프로젝트가 끝난 후 사용한 코드에 대해 복습 목적으로 글을 작성한다. 모델은 총 3개인데 CNN, RNN, Transformer 순으로 정리할 예정이다.
👩🏫 모델 클래스
class CNN(nn.Module):
def __init__(self, vocab_size, embed_dim, n_filters, filter_size, dropout, num_class):
super(CNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.conv1d_layers = nn.ModuleList([nn.Conv1d(in_channels=embed_dim, out_channels=n_filters[i], kernel_size=filter_size[i]) for i in range(len(filter_size))])
self.fc_layer = nn.Linear(np.sum(n_filters), num_class)
self.dropout = nn.Dropout(p=dropout)
def forward(self, sentence):
x_embed = self.embedding(sentence)
x_embed = x_embed.permute(0, 2, 1)
x_conv_list = [F.relu(conv1d(x_embed)) for conv1d in self.conv1d_layers]
x_pool_list = [F.max_pool1d(x_conv, kernel_size=x_conv.shape[2]) for x_conv in x_conv_list]
x_fc_layer = torch.cat([x_pool.squeeze(dim=2) for x_pool in x_pool_list], dim=1)
logits = self.fc_layer(self.dropout(x_fc_layer))
return logits
🎯 파라미터
◽ vocab_size: vocab 크기. vocab에 들어있는 단어의 개수
◽ embed_dim: 임베딩 벡터 차원
◽ n_filters: 합성곱 연산을 위한 필터 개수
◽ filter_size: 한 번에 볼 글자 수
◽ num_class: 타겟이 되는 레이블 수
⏳ 작동 방식
1. __init__
1) nn.Embedding(vocab_size, embed_dim)
◽ vocab_size 행×embed_dim 열 크기의 룩업 테이블 생성
2) nn.ModuleList(~)
◽ 모듈을 리스트 형태로 저장하는 nn.ModuleList()를 이용해 nn.Conv1d 레이어를 filter_size 길이만큼 연결한다. 나는 filter_size = [20, 20, 20]으로 사용했기 때문에 3개의 Conv1d 레이어가 연결된다.
3) nn.Conv1d(in_channels=embed_dim, out_channels=n_filters[i], kernel_size=filter_size[i])
◽ (batch, in_channels, kernel_size)로 구성된 conv1d 레이어와 입력 벡터의 합성곱 연산이 끝났을 때 출력 차원은 (batch, 필터 수, n_out)이다.

⭐ n_out 계산 과정은 PyTorch 공식 문서를 참고했다.
4) nn.Linear(np.sum(n_filters), num_class)
◽ np.sum(n_filters) 차원을 입력으로 받아서 num_class 차원 벡터를 출력한다. nn.Linear 레이어에 입력으로 들어오려면 nn.Linear(~) 0번 인자와 차원이 같아야 한다.
2. forward
1) sentence
◽ 모델 돌릴 때 배치 사이즈는 16, 문장의 max_length는 152로 지정했기 때문에 sentece의 크기는 torch.Size([16, 152])가 된다.
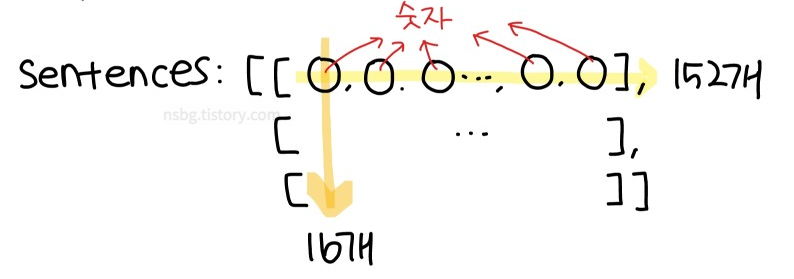
2) x_embed = self.embedding(sentence)
◽ x_embed는 sentence가 임베딩 벡터 크기 100인 임베딩 레이어를 통과한 후 생성되는 벡터이므로 x_embed의 크기는 torch.Size([16, 152, 100])이 된다. → 차원이 하나 더 추가됨
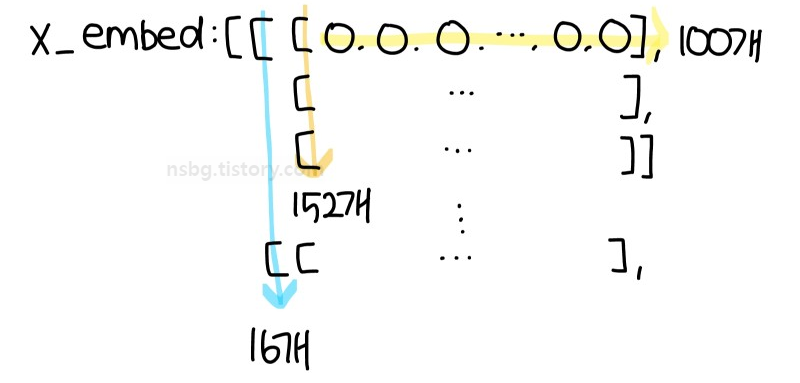
3) x_embed = x_embed.permute(0, 2, 1)
◽ permute 함수는 형 변환 함수인데 (0, 1, 2)의 값들을 적힌 순서대로 변경한다. torch.Size([16, 152, 100])에서 0=16, 1=152, 2=100이므로 permute 함수를 적용한 x_embed의 크기는 torch.Size([16, 100, 152])가 된다.
4) x_conv_list
◽입력 x_embed를 3개의 conv1d 레이어 각각에 통과시켜주고 ReLU 함수를 적용한다. CNN에서는 활성화 함수로 ReLU를 주로 사용한다고 해서 왜 Softmax가 아니지? 라는 생각이 들었는데, 아래 링크가 좋은 답안이 되어 주었다.
5) x_pool_list
◽ 이미지에 CNN을 적용하는 것처럼 MaxPooling1D를 적용하여 합성곱 연산으로 얻은 결과(x_conv_list를 이루고 있는 각각의 conv layer)에서 가장 큰 값을 뽑는다.

6) x_fc_layer
◽ torch.cat(INPUT, dim=1)은 입력 벡터를 두 번째 차원 방향으로 합치라는 의미이다. 예를 들어 2*2 크기의 두 벡터를 dim=1로 주고 합친다면 2*4가 되고 dim=0으로 주고 합친다면 4*2가 되는 식이다.
◽ torch.cat 내부의 '[x_pool.squeeze(dim=2) for x_pool in x_pool_list]'는 x_pool_list를 이루고 있는 x_pool 벡터에서 크기가 1이고 dim=2 위치에 있는 차원만 제거한다는 의미이다.
'👩💻' 카테고리의 다른 글
| [코드 리뷰] 노년층 대화 감성 분류 모델 구현 (3): Transformer ① (0) | 2022.12.27 |
|---|---|
| [코드 리뷰] 노년층 대화 감성 분류 모델 구현 (2) : RNN (0) | 2022.12.21 |
| [ART] attack_adversarial_patch_TensorFlowV2.ipynb 코드 분석 (0) | 2022.01.19 |
| [ART] attack_defence_imagenet.ipynb 코드 실습 (0) | 2022.01.18 |
| [ART] adversarial_training_mnist.ipynb 코드 분석 (0) | 2022.01.12 |